Welcome
Hello and welcome to my site. My name is Loukas Bampis, and I am an Assistant Professor at the Department of Electrical and Computer Engineering, Democritus University of Thrace, Xanthi, Greece. I am also a proud member of the Mechatronics and Systems Automation Lab, working on real-time optomechatronics and robotics applications for mobile platforms and industrial applications.
Research Summary
Optomechatronics systems synergistically combine optical, mechanical, and electrical components to increase the autonomy on various industrial sectors. As the complexity of recent engineering procedures is constantly accelerating, modern optomechatronics are designated to support and promote the interaction between visual sensing and numerous other technologies, such as signal processing, modality fusion, actuation, manipulation, control, task scheduling, efficient hardware and software development, and so on. In order to handle such multidisciplinary architectures, sophisticated cognitive and reasoning skills are necessary. Recent advancements in artificial intelligence have proven its capacity to manage this level of complex integration by combining multiple sources of information and adapting or reconfiguring their function over a broad spectrum of operational conditions.
My research interests focus on exploiting the role of intelligence in increasing the autonomous capabilities of optomechatronics systems. To this end, I am working towards addressing the particular challenges of this field, both from academic and industrial viewpoints.
Interests
- Optomechatronics
- Robotics
- Perception
- Localization and Mapping
- Place Recognition
Colleagues
-
The Mechatronics & Systems Automation Laboratory (MeSA) of the Department of Electrical & Computer Engineering (DECE) of Democritus University of Thrace (DUTh) is one of the oldest laboratories of the Department. It focuses its R&D efforts on innovative ICTs in Mechatronics and Systems Automation. The laboratory is based upon its specialized scientific personnel, computing facilities, and special purpose equipment, including microprocessors, experimental devices, robotic platforms, measurement systems, machine tools, CAD / CAM software, PLC, and data fusion – sensors. The laboratory consists mainly of two faculty members, aided by the Department's technical staff and teaching personnel, by external collaborating researchers and Ph.D. candidates. Research in the MeSA laboratory focuses on mechatronics, systems automation, robotics, analog, and digital electronic systems, measurement systems, instrumentation and measurements, CAD / CAE systems, wind generators, wind data processing, standards, and certification. MeSA laboratory has a long experience in R&D projects targeting data fusion, as well as sensors with applications in robotics and automation. These projects involved computer architectures, microprocessors, and their applications in intelligent and autonomous robots (humanoids, animated, underwater, flying, etc.).
[ Visit MeSA Lab ] -

The Laboratory of Robotics and Automation performs and promotes research in application problems that arise in the area of robotics, computer vision, navigation, multimodal integration, image analysis and understanding, visual surveillance, intelligent sensory networks, sensory fusion, and other relative topics.
The lab utilizes state of the art tools to expand the scientific and technological front in the respective research areas, namely: artificial vision (including cognitive and robot Vision); intelligent systems (such as artificial neural networks); pattern recognition.
[ Visit LRA ]
Projects
-
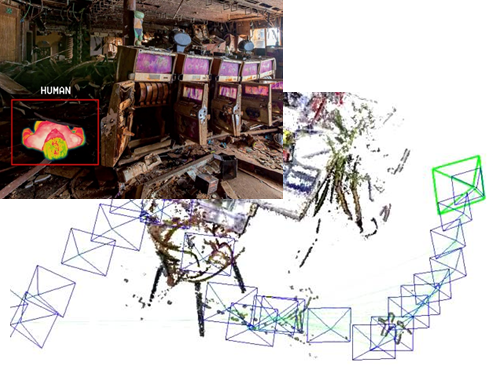
The MIDRES project will develop a mini UAV capable of exploring hazardous sites for mapping and detecting humans in need. Towards this end, state-of-the-art SLAM and path planning techniques will be exploited, enabling the platform to effectively perceive the environment and interact with its surroundings.
T2EDK-00592, RESEARCH–CREATE–INNOVATE
-

The goal of MPU is to develop a commercial multipurpose UAV that uniquely combines fixed-wing flight and VTOL capabilities. Its advanced autonomous flight and obstacle avoidance systems ensure safe and efficient operation on a pre-defined trajectory. Its modular design offers low weight, high portability, and payload versatility.
T1EDK-00737, RESEARCH–CREATE–INNOVATE
-

The Flawless project aims at developing an autonomous intelligent solution capable of recognizing item defects and self-correcting the systems involved in a production line through smart sensors.
T2EDK-01658, RESEARCH–CREATE–INNOVATE
-

The AVERT project developed an autonomous security system capable of removing any blocking or suspect vehicle from vulnerable positions such as enclosed infrastructure spaces, tunnels, low bridges, as well as under-building and underground car parks. Vehicles can be removed from confined areas with delicate handling, swiftly, and in any direction to a safer disposal point to reduce or eliminate collateral damage to infrastructure and personnel. Remote operation, self-powered and onboard sensors provide a new capability to operate alongside existing technologies, thereby enhancing bomb disposal response, speed, and safety.
FP7-SEC-2011-1-285092, European Commission – Information & Communication Technologies (ICT).
-

The NOAH activity was founded by the European Space Agency (ESA). This project improved the state-of-the-art of novelty detection techniques specifically for Mars-like environments.
T713-503MM, European Space Agency
[ Visit NOAH ] -

ESTIA developed an integrated platform for forecasting, detecting, and managing crises related to fire risk within a residential environment that is part of the immovable cultural heritage.
T1EDK-03582, RESEARCH–CREATE–INNOVATE
[ Visit ESTIA ] -

The HCUAV project developed a surveillance MALE UAV capable of flying autonomously for long distances. The platform's goal was to create a georeferenced map of the world underneath and detect emergency response instances using RGB and thermal cameras.
11SYNERGASIA_9_629, National Strategic Reference Framework (NSRF) – Competitiveness & Entrepreneurship – SYNERGASIA 2011
-

The YPOPSEI project, run by the research committee of the Athena Research and Innovation Centre, refers to a user application with which a museum visitor can obtain information regarding an exhibition that he is interested in by simply capturing it with their mobile device.
MIS code:5006383, Human Resources Development, Education and Lifelong Learning
-

During my visit to the Multiple Autonomous Robotic Systems Lab in the University of Minneapolis (MarsLab), run by Professor Stergios Roumeliotis, I contributed to his research activities by implementing a variety of accelerated versions of robotics vision and estimation theory algorithms. I participated in Google’s Project Tango (currently incorporated into ARCore), which created a mobile device capable of localizing itself and estimating the structure of its surrounding world in real-time for indoor environments where GPS measurements are not available. Instead, this was achieved using sensors like RGB/RGBD cameras, accelerometers, and gyroscopes, all included in one device.
[ Visit MarsLab ]
Publications
You can find out more about my research by referring to my scientific papers here or by hitting Google Scholar.
Filter by type:
Sort by year:
Fast Loop Closure Detection using Visual-Word-Vectors from Image Sequences
Journal Paper The International Journal of Robotics Research (IJRR), 2017, Pages -.
Abstract
In this paper, a novel pipeline for loop-closure detection is proposed. We base our work on a bag of binary feature words and we produce a description vector capable of characterizing a physical scene as a whole. Instead of relying on single camera measurements, the robot’s trajectory is dynamically segmented into image sequences according to its content. The visual word occurrences from each sequence are then combined to create sequence-visual-word-vectors and provide additional information to the matching functionality. In this way, scenes with considerable visual differences are firstly discarded, while the respective image-to-image associations are provided subsequently. With the purpose of further enhancing the system’s performance, a novel temporal consistency filter (trained offline) is also introduced to advance matches that persist over time. Evaluation results prove that the presented method compares favorably with other state-of-the-art techniques, while our algorithm is tested on a tablet device, verifying the computational efficiency of the approach.
High Order Visual Words for Structure-Aware and Viewpoint-Invariant Loop Closure Detection
Conference Paper IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2017.
Abstract
In the field of loop closure detection, the most conventional approach is based on the Bag-of-Visual-Words (BoVW) image representation. Although well-established, this model rejects the spatial information regarding the local feature points' layout and performs the associations based only on their similarities. In this paper we propose a novel BoVW-based technique which additionally incorporates the operational environment's structure into the description, treating bunches of visual words with similar optical flow measurements as single similarity votes. The presented experimental results prove that our method offers superior loop closure detection accuracy while still ensuring real-time performance, even in the case of a low power consuming mobile device.
Encoding the Description of Image Sequences: A Two-Layered Pipeline for Loop Closure Detection
Conference Paper IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2016, Pages 4530-4536.
Abstract
In this paper we propose a novel technique for detecting loop closures on a trajectory by matching sequences of images instead of single instances. We build upon well established techniques for creating a bag of visual words with a tree structure and we introduce a significant novelty by extending these notions to describe the visual information of entire regions using Visual-Word-Vectors. The fact that the proposed approach does not rely on a single image to recognize a site allows for a more robust place recognition, and consequently loop closure detection, while reduces the computational complexity for long trajectory cases. We present evaluation results for multiple publicly available indoor and outdoor datasets using Precision-Recall curves, which reveal that our method outperforms other state of the art algorithms.
A LoCATe-based Visual Place Recognition System for Mobile Robotics and GPGPUs
Journal Paper Concurrency and Computation: Practice and Experience (accepted for publication), 2017, Pages -.
Abstract
In this paper, a novel visual Place Recognition (vPR) approach is evaluated based on a visual vocabulary of the Color and Edge Directivity Descriptor (CEDD) in order to address the loop closure detection task. Even though CEDD was initially designed so as to globally describe the color and texture information of an input image addressing Image Indexing and Retrieval tasks, its scalability on characterizing single feature points has already been proven. Thus, instead of using CEDD as a global descriptor, we adopt a bottom-up approach and utilize its localized version, Local Color And Texture dEscriptor (LoCATe), as an input to a state-of-the-art visual Place Recognition technique based on Visual Word Vectors. Also, we employ a parallel execution pipeline based on a previous work of ours using the well-established GPGPU computing. Our experiments show that the usage of CEDD as a local descriptor produces high accuracy vPR results, while the parallelization employed allows for a real-time implementation even in the case of a low-cost mobile device.
Accelerating single-image super-resolution polynomial regression in mobile devices
Journal Paper Transactions on Consumer Electronics<, Volume 61, Number 1, 2015, Pages 63-71.
Abstract
This paper introduces a new super-resolution algorithm based on machine learning along with a novel hybrid implementation for next generation mobile devices. The proposed super-resolution algorithm entails a two dimensional polynomial regression method using only the input image properties for the learning task. Model selection is applied for defining the optimal degree of polynomial by adopting regularization capability in order to avoid overfitting. Although it is widely believed that machine learning algorithms are not appropriate for real-time implementation, the paper in hand proves that there are indeed specific hypothesis representations that are able to be integrated into real-time mobile applications. With aim to achieve this goal, the increasing GPU employment in modern mobile devices is exploited. More precisely, by utilizing the mobile GPU as a co-processor in a hybrid pipelined implementation, significant performance speedup along with superior quantitative results can be achieved.
Real-time surveillance detection system for medium-altitude long-endurance unmanned aerial vehicles
Journal Paper Concurrency and Computation: Practice and Experience, 2017, Pages -.
Abstract
The detection of ambiguous objects, although challenging, is of great importance for any surveillance system and especially for an Unmanned Aerial Vehicle (UAV), where the measurements are affected by the great observing distance. Wildfire outbursts and illegal migration are only some of the examples that such a system should distinguish and report to the appropriate authorities. More specifically, Southern European countries commonly suffer from those problems due to the mountainous terrain and thick forests that contain. UAVs like the "Hellenic Civil Unmanned Air Vehicle - HCUAV" project have been designed in order to address high altitude detection tasks and patrol the borders and woodlands for any ambiguous activity. In this paper, a moment-based blob detection approach is proposed that utilizes the thermal footprint obtained from single infrared (IR) images and distinguishes human or fire sized and shaped figures. Our method is specifically designed so as to be appropriately integrated into hardware acceleration devices, such as GPGPUs and FPGAs, and takes full advantage of their respective parallelization capabilities succeeding real-time performances and energy efficiency. The timing evaluation of the proposed hardware accelerated algorithm's adaptations shows an achieved speedup of up to 7 times, as compared to a highly optimized CPU-only based version.
Exploring CNN Based Anomaly Detection for Robotic Mars Exploration Missions
Abstract Paper 14th Symposium on Advanced Space Technologies in
Robotics and Automation (ASTRA), 2017, Pages -.
Abstract
A visual anomaly detection algorithm typically incorporates two modules, namely the Region Of Interest (ROI) detection and the ROI characterization. During the first module, salient image regions are identified containing semantically distinctive entities, while the second one refers to the characterization of the detected ROIs as "novel" (unable of being classified) or "known" (capable of being classified into one of the pre-trained classes). In this paper, we are interested in investigating a unified solution that treats the ROI detection and characterization functionalities as a single task using the classification properties of the Convolutional Neural Networks (CNNs).
Can Speedup Assist Accuracy? An on-board GPU-Accelerated Image Georeference Method for UAVs
Conference Paper International Conference on Computer Vision Systems, 2015, Pages 104-114.
Abstract
This paper presents a georeferenced map extraction method, for Medium-Altitude Long-Endurance UAVs. The adopted technique of projecting world points to an image plane is a perfect candidate for a GPU implementation. The achieved high frame rate leads to a plethora of measurements even in the case of a low-power mobile processing unit. These measurements can later be combined in order to refine the output and create a more accurate result.
The HCUAV project: Electronics and software development for medium altitude remote sensing
Conference Paper International Symposium on Safety, Security, and Rescue Robotics, 2014, Pages 1-5.
Abstract
The continuous increase of illegal migration flows to southern European countries has been recently in the spotlight of European Union due to numerous deadly incidents. Another common issue that the aforementioned countries share is the Mediterranean wildfires which are becoming more frequent due to the warming climate and increasing magnitudes of droughts. Different ground early warning systems have been funded and developed across these countries separately for these incidents, however they have been proved insufficient mainly because of the limited surveyed areas and challenging Mediterranean shoreline and landscape. In 2011, the Greek Government along with European Commission, decided to support the development of the first Hellenic Civil Unmanned Aerial Vehicle (HCUAV), which will provide solutions to both illegal migration and wildfires. This paper presents the challenges in the electronics and software design, and especially the under development solutions for detection of human and fire activity, image mosaicking and orthorectification using commercial off-the-shelf sensors. Preliminary experimental results of the HCUAV medium altitude remote sensing algorithms, show accurate and adequate results using low cost sensors and electronic devices.
Real-time indexing for large image databases: Color and Edge Directivity Descriptor on GPU
Journal Paper The Journal of Supercomputing, Volume 71, Number 3, 2015, Pages 909-937.
Abstract
In this paper, we focus on implementing the extraction of a well-known low-level image descriptor using the multicore power provided by general-purpose graphic processing units (GPGPUs). The color and edge directivity descriptor, which incorporates both color and texture information achieving a successful trade-off between effectiveness and efficiency, is employed and reassessed for parallel execution. We are motivated by the fact that image/frame indexing should be achieved real time, which in our case means that a system should be capable of indexing a frame or an image as it becomes part of a database (ideally, calculating the descriptor as the images are captured). Two strategies are explored to accelerate the method and bypass resource limitations and architectural constrains. An approach that exclusively uses the GPU together with a hybrid implementation that distributes the computations to both available GPU and CPU resources are proposed. The first approach is strongly based on the compute unified device architecture and excels compared to all other solutions when the GPU resources are abundant. The second implementation suggests a hybrid scheme where the extraction process is split in two sequential stages, allowing the input data (images or video frames) to be pipelined through the central and the graphic processing units. Experimental results were conducted on four different combinations of GPU–CPU technologies in order to highlight the strengths and the weaknesses of all implementations. Real-time indexing is obtained over all computational setups for both GPU-only and Hybrid techniques. An impressive 22 times acceleration is recorded for the GPU-only method. The proposed Hybrid implementation outperforms the GPU-only implementation and becomes the preferred solution when a low-cost setup (i.e., more advanced CPU combined with a relatively weak GPU) is employed.
Image Encryption Using the Recursive Attributes of the eXclusive-OR Filter
Journal Paper Journal of Cellular Automata, Volume 9, Number 2-3, 2014, Pages 125-137
Abstract
This paper describes a visual multimedia content encryption approach based on cellular automata (CA), expanding the work proposed in [4]. The presented algorithm relies on an attribute of the eXclusive-OR (XOR) filter, according to which, the original content of a cellular neighborhood can be reconstructed following a predefined number of applications of the filter. During the interim time marks, the cellular neighborhood is greatly distorted, making it impossible to be recognized. The application of this attribute to the field of image processing, results to a strong visual multimedia content encryption approach. Additionally, this paper proposes a new approach for the acceleration of the application of the XOR-filter, taking advantage of the Summed Area Tables (SAT) approach.
Digital elevation model fusion using spectral methods
Conference Papers International Conference on Imaging Systems and Techniques, 2014, Pages 340-345.
Abstract
This paper presents the application of different spectral methods, like Fourier series and polynomial-based expansions, to Digital Elevation Models (DEMs) in order to fuse their content. Two different fusion techniques: 1) a filter-based one and 2) a weighted average of expansion coefficients, are examined. Their performance is evaluated by using both ground-truth lidar data as well as fusion quality measures. The results point out that polynomial-based spectral expansions perform better than the traditional Fourier approach.
Accelerating image super-resolution regression by a hybrid implementation in mobile devices
Conference Paper International Conference on Consumer Electronics, 2014, Pages 335-336.
Abstract
This paper introduces a new super-resolution algorithm based on machine learning along with a novel hybrid implementation for next generation mobile devices. The proposed super-resolution algorithm entails a multivariate polynomial regression method using only the input image properties for the learning task. Although it is widely believed that machine learning algorithms are not appropriate for real-time implementation, the paper in hand proves that there are indeed specific hypothesis representations that are able to be integrated into real-time mobile applications. With aim to achieve this goal, we take advantage of the increasing GPU employment in modern mobile devices. More precisely, we utilize the mobile GPU as a co-processor in a hybrid pipelined implementation achieving significant performance speedup along with superior quantitative interpolation results.
Color and Edge Directivity Descriptor on GPGPU
Conference Paper International Conference on Parallel, Distributed, and Network-Based Processing, 2015, Pages 301-308.
Abstract
Image indexing refers to describing the visual multimedia content of a medium, using high level textual information or/and low level descriptors. In most cases, images and videos are associated with noisy and incomplete user-supplied textual annotations, possibly due to omission or the excessive cost associated with the metadata creation. In such cases, Content Based Image Retrieval (CBIR) approaches are adopted and low level image features are employed for indexing and retrieval. We employ the Colour and Edge Directivity Descriptor (CEDD), which incorporates both colour and texture information in a compact representation and reassess it for parallel execution, utilizing the multicore power provided by General Purpose Graphic Processing Units (GPGPUs). Experiments conducted on four different combinations of GPU-CPU technologies revealed an impressive gained acceleration when using a GPU, which was up to 22 times faster compared to the respective CPU implementation, while real-time indexing was achieved for all tested GPU models.
Associate Editor
Since 2021, I serve as an Associate Editor for Electronics Letters, IET. I was also a Guest Editor at the same journal, where I contributed to the publication of Deep Learning and Robotics Special Issue.
Reviewer
Together with my ongoing research, I have also contributed to the scientific community as a reviewer on numerous scientific conference and journal papers for IEEE Transactions on Robotics, Intelligent Service Robotics, Robotics and Automation Systems, International Conference on Intelligent Robots and Systems, International Conference on Robotics and Automation, Electronics Letters, Image and Vision Computing, and more.
Teaching
Fall Semester
Spring Semester
Diploma Theses

Contact
- +30 (25410) 71981
-
 lbampis@ee.duth.gr
lbampis@ee.duth.gr
- Loukas.Bampis
- linkedin.com/in/loukas-bampis
-
Loukas Bampis,
Democritus University of Thrace,
Department of Electrical and Computer Engineering,
Power Systems Sector,
Mechatronics & Systems Automation Laboratory,
GR-67100, Xanthi, Greece
GitHub repository
Visit my GitHub repository here.